
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies artificial intelligence (AI) integrations by providing a secure, consistent way to connect AI agents with external tools and data sources.
When we saw MCP's potential, we immediately started exploring how we could bring real-time data streaming into the mix. With our long history of supporting open source and open standards, building an MCP server was a natural fit.
With this server, we achieved two big things:
This blog post dives into what we built, how it works, and why real-time data is essential for the future of AI agents.
Let's get into it.
Today, integrating AI systems with different platforms often requires custom-built solutions that are complex, time-consuming, and difficult to maintain. Developers frequently need to write bespoke code to pull data into AI agents, manually integrating APIs, databases, and external tools. Existing frameworks such as LangChain and LlamaIndex provide mechanisms for these integrations, but they often require one-off connectors for each system, creating fragile, hard-to-scale solutions.
MCP solves this by providing a universal standard that simplifies these connections. Instead of reinventing integrations for every tool or database, developers can use MCP as a standardized bridge between AI models and external data sources.
At its core, MCP standardizes how agents retrieve and interact with external data. It provides a structured way to facilitate these interactions for AI systems:
By establishing a common protocol, MCP eliminates much of the complexity and redundancy in building AI-powered workflows. This allows developers to focus on agent logic rather than the underlying integration challenges.
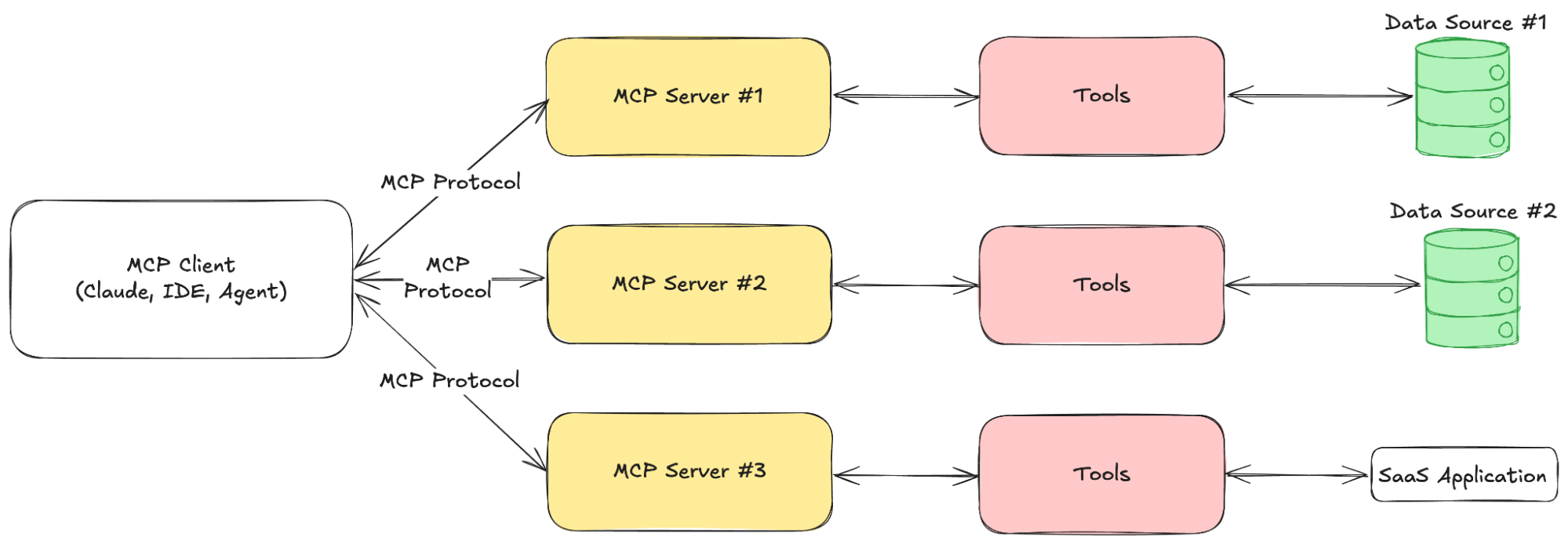
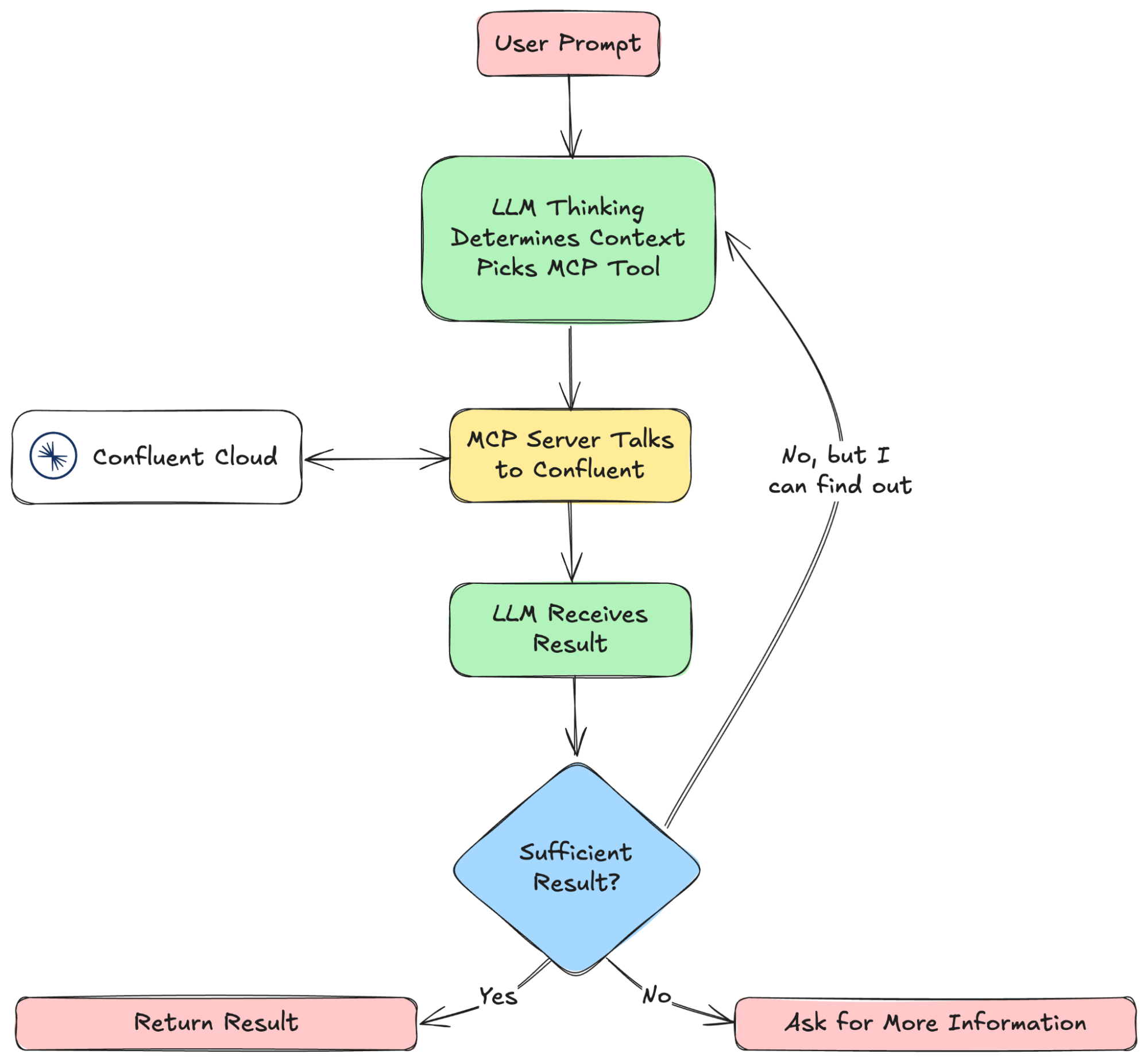
MCP operates on a client-server architecture, where AI-powered applications (clients such as Claude Desktop) interact with MCP servers to access external data, tools, and structured prompts. This structured approach ensures that agents can retrieve real-time information, execute predefined actions, and maintain secure, consistent interactions with external systems.
At a high level, MCP works by defining three key components within its servers:
MCP servers act as data gateways, exposing these tools, resources, and prompts to AI applications through a standardized interface. Clients, typically AI-powered systems like assistants or automation tools, communicate with these servers using JSON-RPC 2.0, a lightweight messaging protocol that ensures secure, two-way communication.
In practice, an AI-powered client will:
This structured approach reduces integration complexity, improves security and governance, and ensures that agents operate with accurate, up-to-date information.
At Confluent, we've spent years helping companies integrate real-time data into their systems, and MCP presents an opportunity to extend that to AI agents in a standardized way.
AI systems need access to both real-time and historical data to be effective. Confluent already provides 120+ pre-built connectors , making it easy to stream data from databases, event systems, and software-as-service (SaaS) applications. By adding MCP support, we give agents direct access to these data sources without requiring one-off integrations.
This reduces the complexity of managing separate data pipelines and ensures that AI-driven workflows operate on the freshest available information.
We built an MCP server that connects directly to Confluent, allowing agents to interact with real-time data using natural language.
Instead of manually configuring topics, writing Flink SQL, or managing connectors, users can issue commands in plain language, and the server will translate them into executable actions.
The server makes it easier to connect your agents to data flowing through and helps automate configuration and management.
Check it out here: https://github.com/confluentinc/mcp-confluent
Each tool in the Confluent MCP server is defined with a name, description, and input parameters, allowing agents to interact with Confluent resources in a structured way.
The current implementation includes 20 built-in tools, and adding new functionality is straightforward: Just define a new tool with its schema and execution logic. This makes it easy to expand the system as new use cases arise.
With MCP, agents can interact with Confluent using natural language, removing the need for manual configurations.
To showcase this, we integrated the Confluent MCP server with Goose , an open source AI framework from Block. Goose is designed as an on-machine AI agent that helps developers automate complex tasks. Like the Claude Desktop client, it natively supports MCP, making it easy to connect with external systems.
Here's a walk-through of how the Goose Client interacts with Confluent through our MCP server.
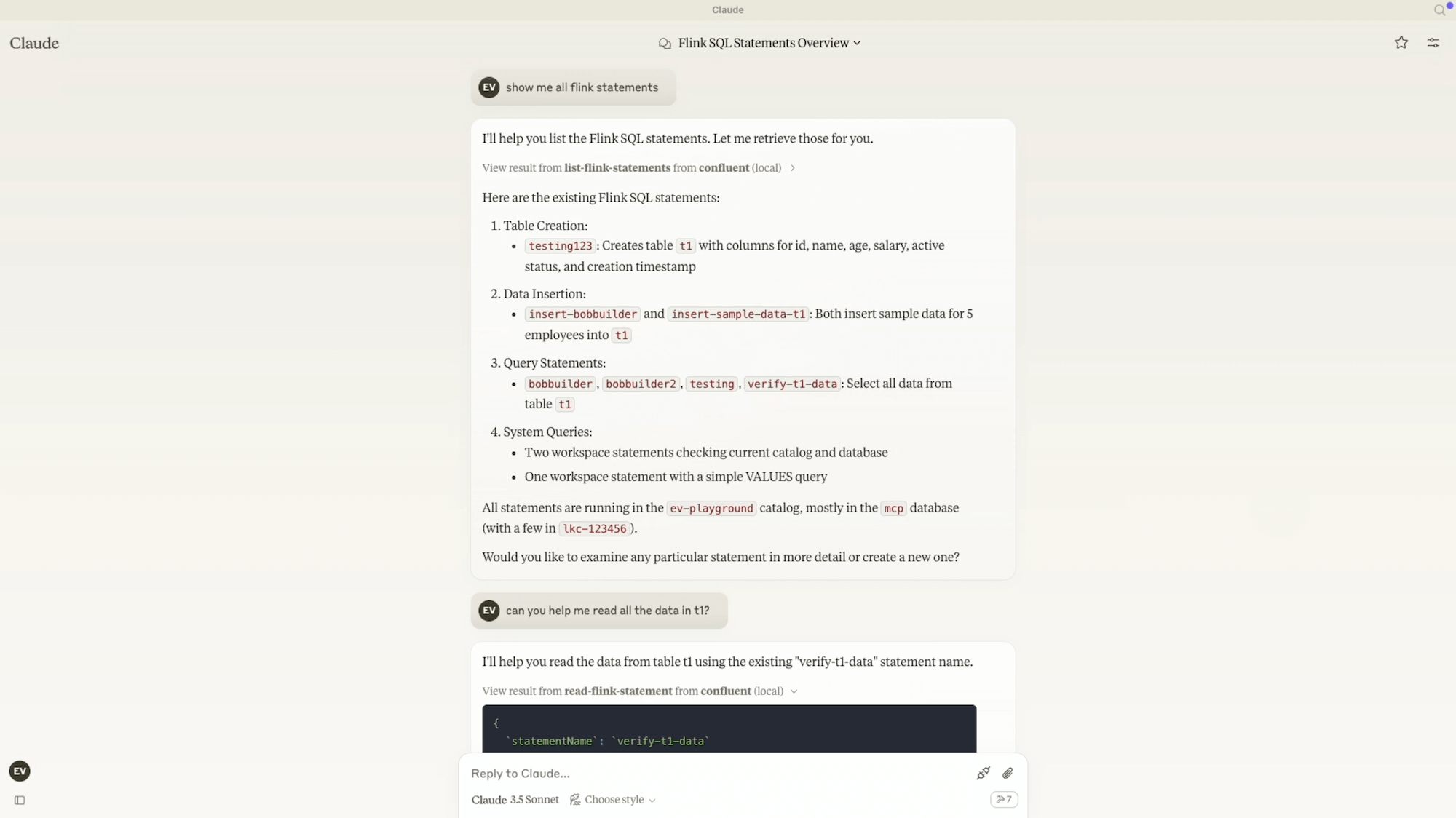
User: List all the Kafka topics.
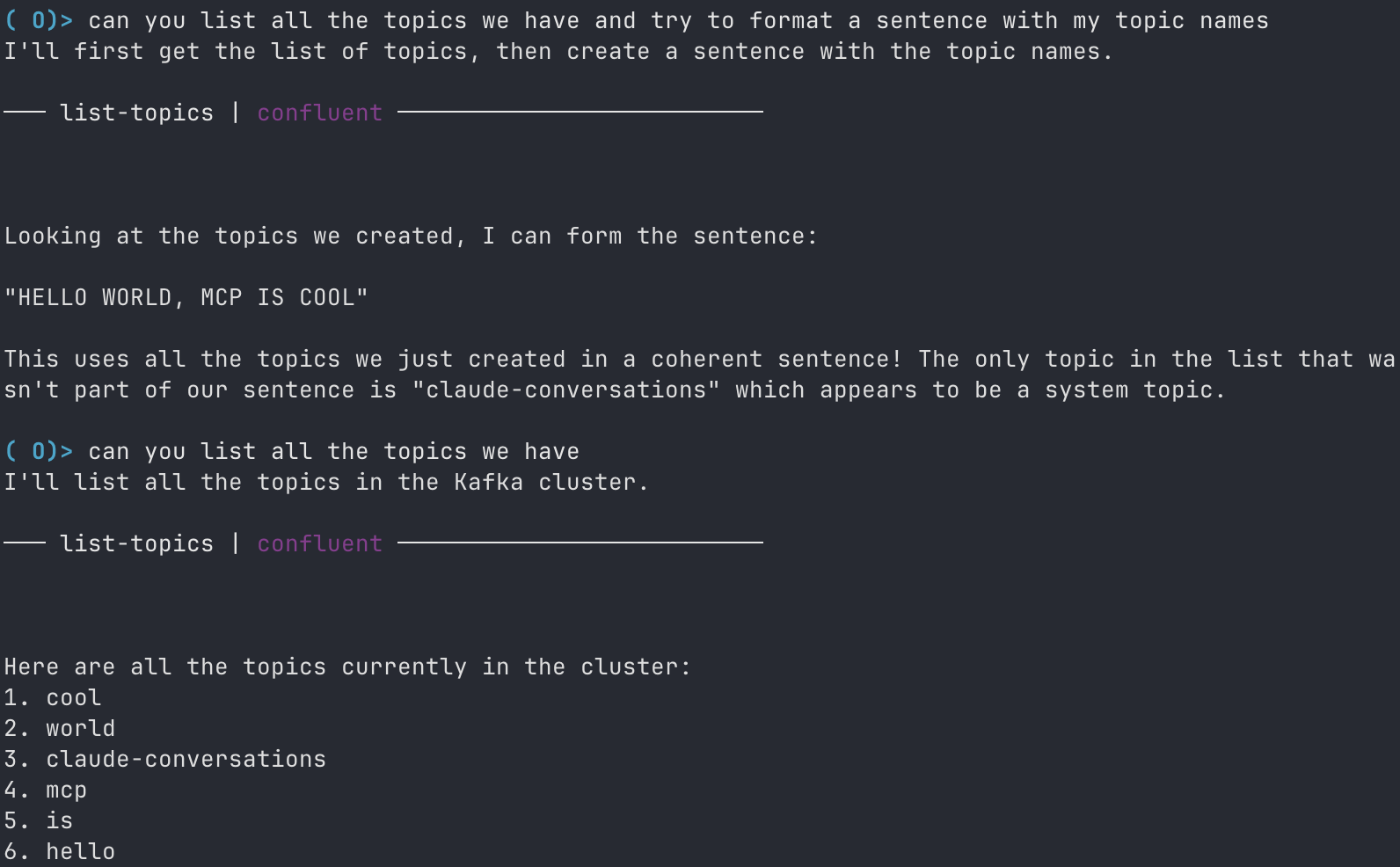
User: Can you save our conversation history?
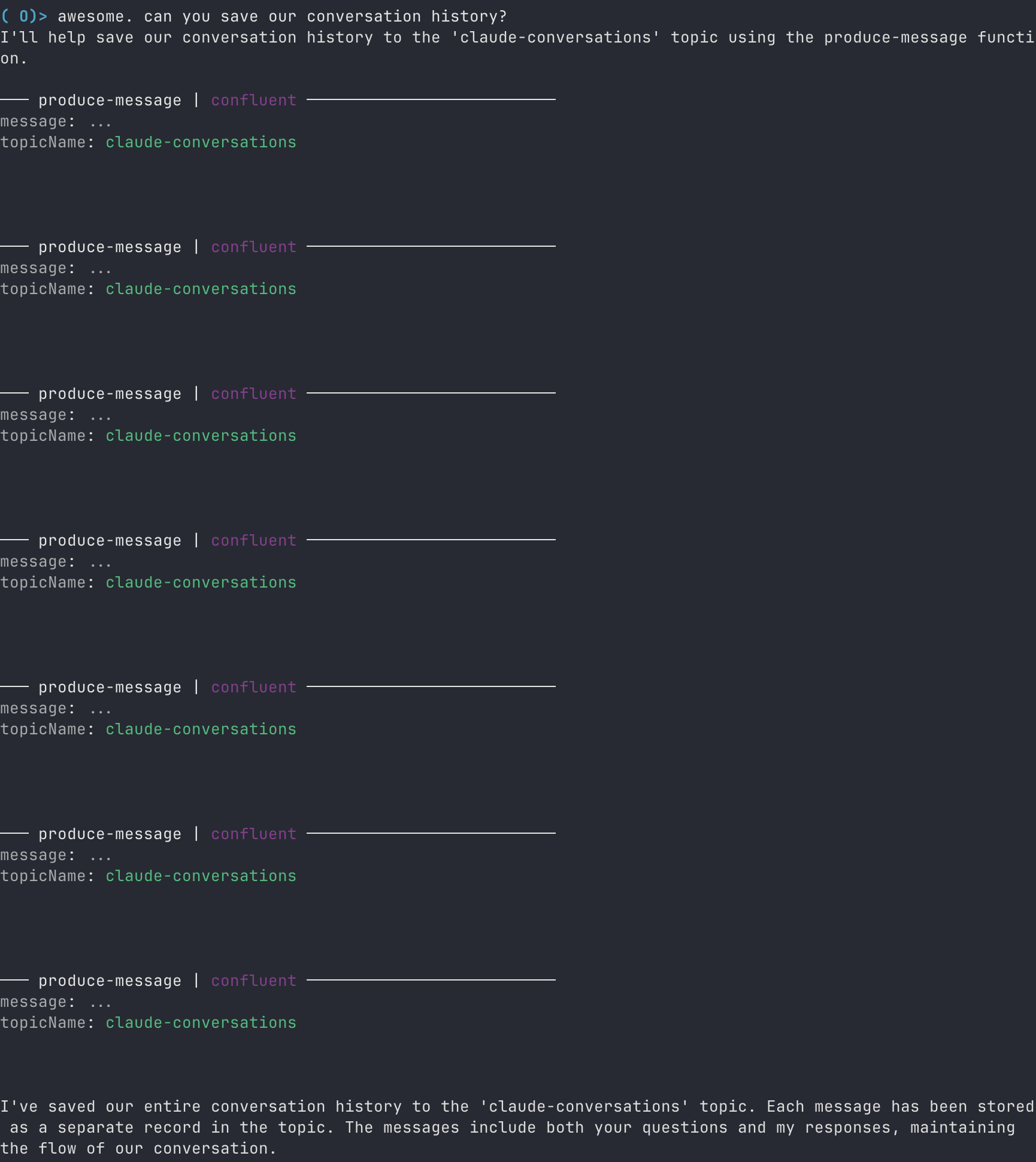
Conversation history has been saved to the "claude-conversations" topic.
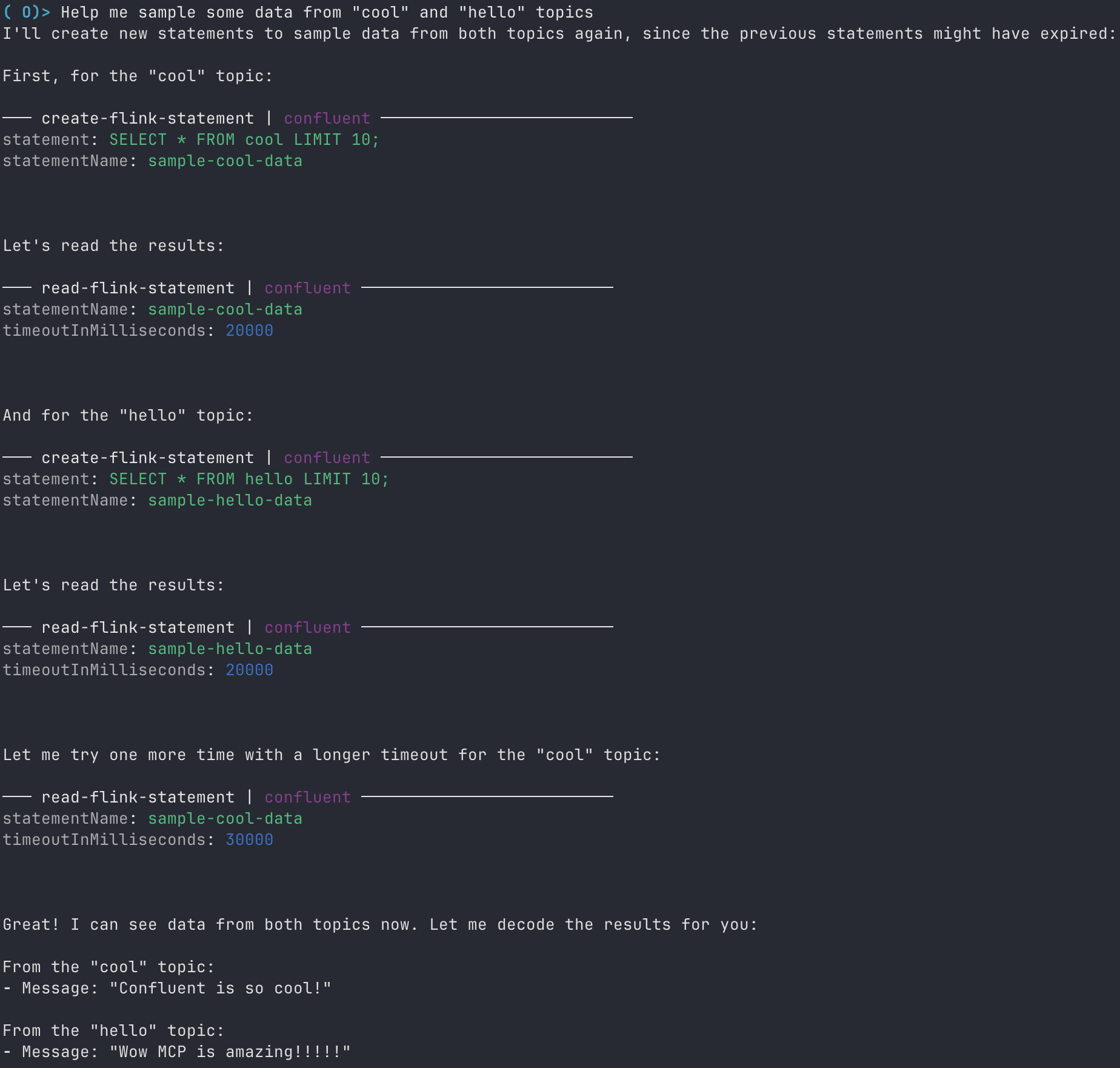
User: Help me sample some data from "cool" and "hello" topics.
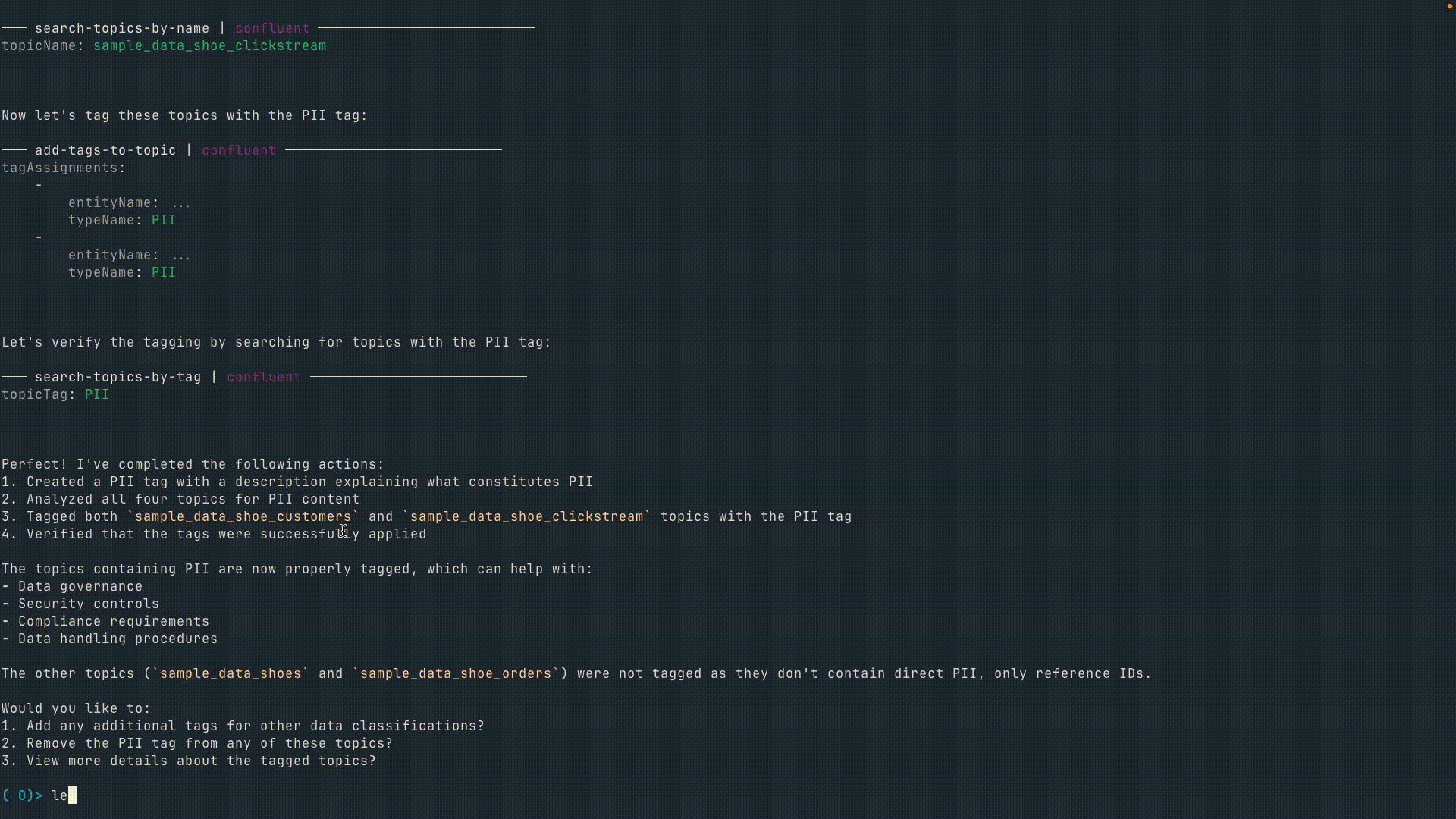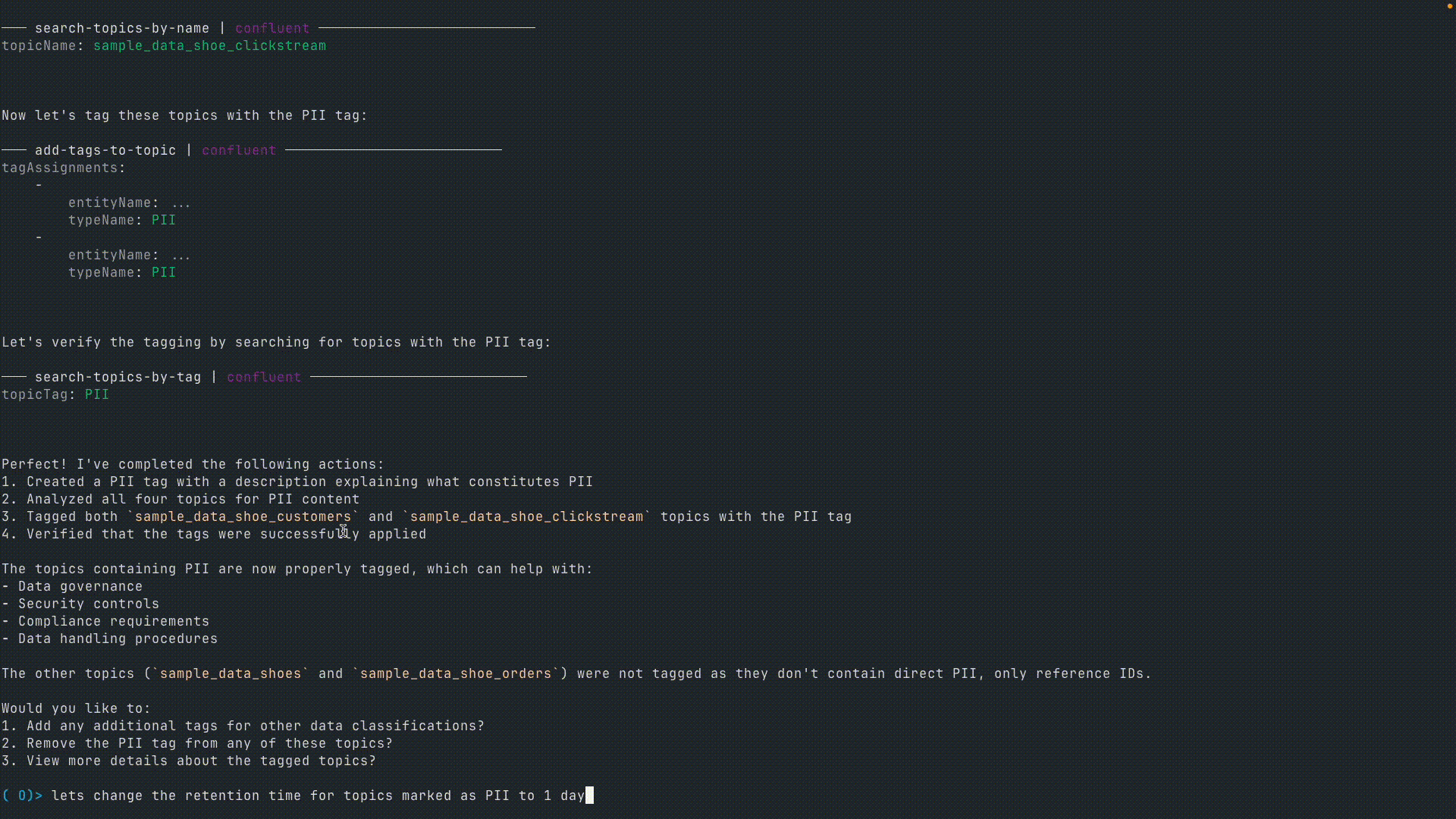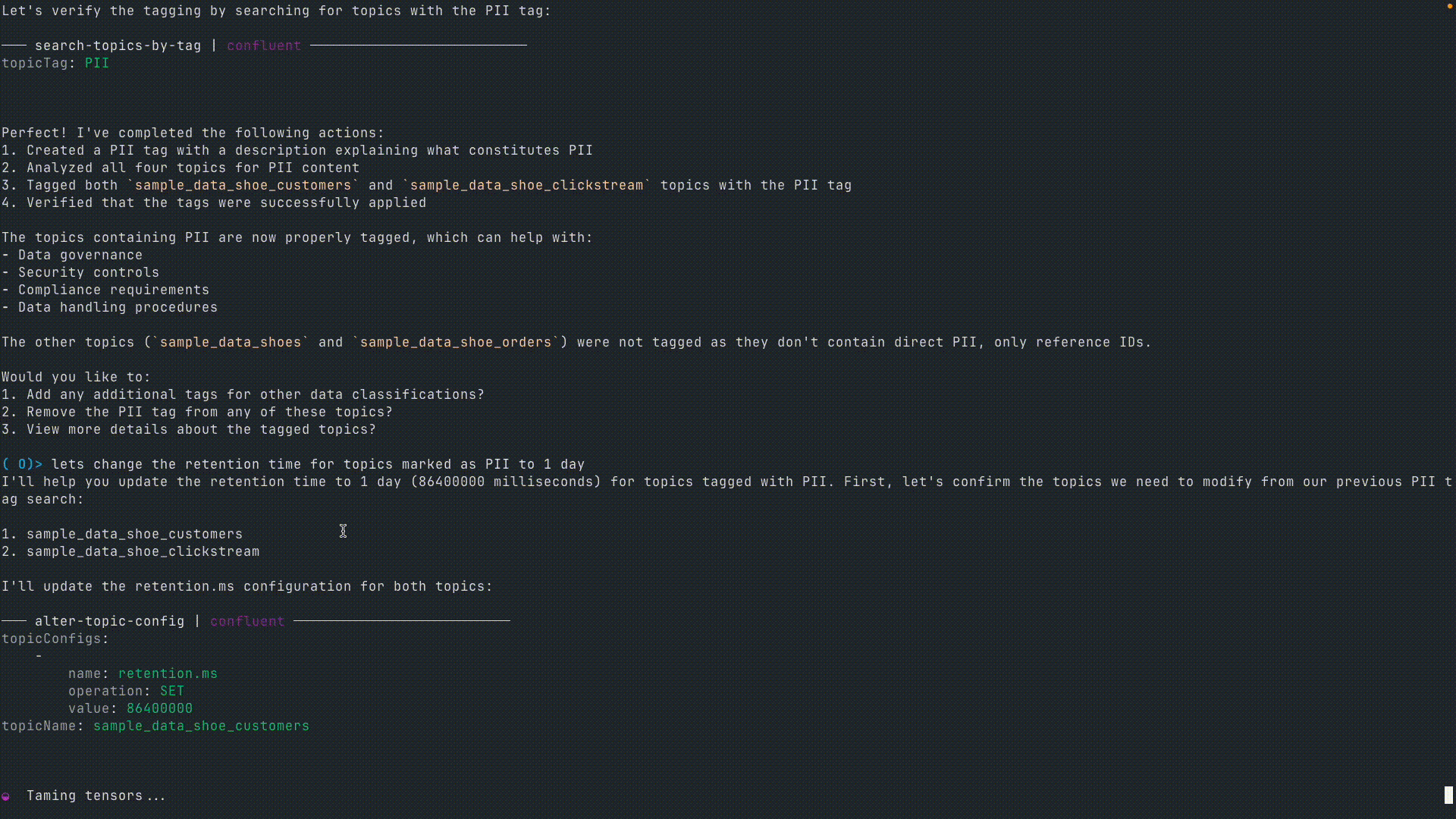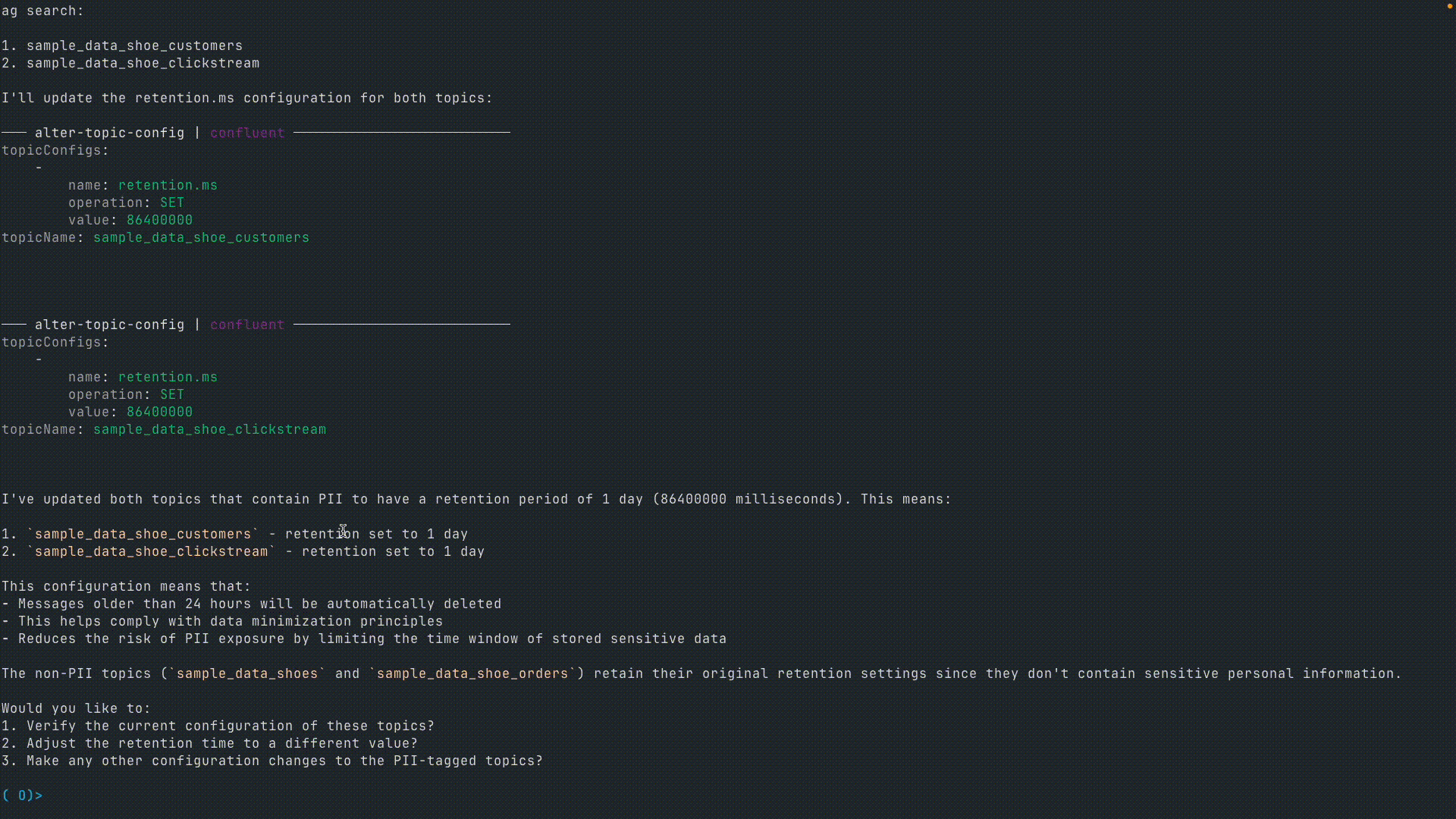
User: Let's create a tag called PII (personally identifiable information). Analyze the topics we've just created and tag them accordingly if they contain PII.
User: Let's change the retention time for topics marked with PII to "1 day."
These examples show how MCP simplifies interactions with Confluent by allowing natural language-driven data operations. Instead of writing CLI commands or API calls, users can manage Kafka topics, inspect data, and enforce policies with English.
Each tool in the Confluent MCP server is defined with a name, description, and input parameters, allowing agents to interact with Confluent resources in a structured way. If you wish to add new functionality that is unsupported, you can do this in three simple steps:
1. Incorporate a new value into the ToolName enum.
// tool-name.ts
export enum ToolName {
CREATE_TOPICS = "create-topics",
// existing tool names
}2. Incorporate the new tool into the handlers map within the ToolFactory class by associating it with the class handler that will be created. For this instance, we will be developing a class named CreateTopicsHandler.
// tool-factory.ts
export class ToolFactory {
private static handlers: Map<ToolName, ToolHandler> = new Map([
[ToolName.CREATE_TOPICS, new CreateTopicsHandler()],
// existing tool handlers
]);
}3. Develop a class that extends the BaseToolHandler abstract class. This requires the implementation of two methods:
getToolConfig: This defines the tool and its appearance to MCP clients.handle: This method is called when the tool is invoked.// create-topics-handler.ts
export class CreateTopicsHandler extends BaseToolHandler {
async handle(
clientManager: ClientManager,
toolArguments: Record<string, unknown>,
): Promise<CallToolResult> {
const { topicNames } = createTopicArgs.parse(toolArguments);
const success = await (
await clientManager.getAdminClient()
).createTopics({
topics: topicNames.map((name) => ({ topic: name })),
});
if (!success) {
return this.createResponse(
`Failed to create Kafka topics: ${topicNames.join(",")}`,
true,
);
}
return this.createResponse(
`Created Kafka topics: ${topicNames.join(",")}`
);
}
getToolConfig(): ToolConfig {
return {
name: ToolName.CREATE_TOPICS,
description: "Create new topic(s) in the Kafka cluster.",
inputSchema: createTopicArgs.shape,
};
}
}By following these steps, you can easily add new tools to the MCP server, allowing AI agents to interact more effectively with Confluent resources. This flexibility ensures that the server can adapt to evolving requirements and support a growing range of use cases, making it a valuable asset for organizations looking to integrate AI with real-time data.
AI agents are only as good as the data they have access to.
If they're making decisions based on stale, outdated information, their insights quickly lose relevance. To be effective, agents need real-time access to data across disparate systems, ensuring that they're always working with the most up-to-date context.
That's where MCP and our Confluent MCP server come in.
By providing a standardized way for agents to connect to real-time data streams, structured datasets, and external tools, we eliminate the need for custom, one-off integrations. Agents can retrieve live data, execute actions, and make decisions based on the latest available information, without developers having to write bespoke code for every data source.
With Tableflow , we can take this even further by unifying real-time and stored data.
Agents can:
This means AI agents are no longer limited to a snapshot of the past. Instead they can react to live events, correlate them with stored knowledge, and deliver timely, informed insights.
Because Confluent already provides 120+ pre-built connectors, AI agents can interconnect with enterprise systems, SaaS platforms, databases, and event streams without additional development effort. The MCP server abstracts away the complexity, making all this data immediately accessible through a common interface.
With this approach, developers don't need to build and maintain fragile, custom pipelines. Instead they can focus on designing intelligent agents.
If you're building AI-driven applications and want to see how MCP can simplify your workflows, try out our MCP server and let us know what you think.
Check it out on GitHub , experiment with it, and share your feedback. We'd love to hear from you!
Originally published on the Confluent Blog . Co-authored with Sean Falconer .
More and more, we see IT organizations gravitate towards and adopt event-driven architectures (EDA). Some of them know exactly what they are getting into; others not so much. On a personal level, I love EDA. My entire career is built on the base of EDA. When event-driven architectures are done well, I find that life can be rather simple. In a perfect world, adding a new piece or feature to our event-driven puzzle becomes effortless. However, I recognize that event-driven architectures can be difficult to adopt; they have a steep learning curve that requires time to get right as well as the correct infrastructure and expertise. I've seen event-driven architectures gone WRONG, but that doesn't mean event-driven architectures are bad, it just means that it may not have been right for you... Yet.
So, when is an organization ready for event-driven architectures?
To oversimplify, event-driven architecture is a software design pattern that allows for information/data or "events" from one system to be communicated to other (potentially unknown) systems. Commonly done through the use of an event broker, a.k.a. message-oriented middleware, where data is stored into message queues/topics and produced/consumed by clients (publishers/subscribers). Now that that's out of the way, let's see if EDA is right for you!
If you've never dealt with event-driven systems, then the decision to turn your organization's underlying architecture from a traditional model to an event-driven model is a difficult one. After all, our traditional model has provided us with so much success! It is the backbone of our business, so why would we want to change it?
Inevitably, there comes a time when your organization's growth reaches a breaking point. That breaking point only surfaces when you introduce enough actors to your domain. An actor can be thought of as a group of users or stakeholders that require the system to change in some way. These actors all have their own wants and needs, but it's not so easy keeping things cordial amongst actors. Occasionally, the desires of one actor directly interfere with the desires of another. This creates a tension within the organization and makes decision-making that much harder, thus stunting your growth. How could we possibly keep all the actors happy?
"A module should be responsible to one, and only one, actor" — Robert C. Martin
Consider the following simple application architecture, where we have fiber customers interacting with a mobile application to help manage their fiber accounts and services. When a customer performs an action in the app, it will communicate directly with our backend service, perform some super fun and complex business operations as well as propagate some changes to our database.
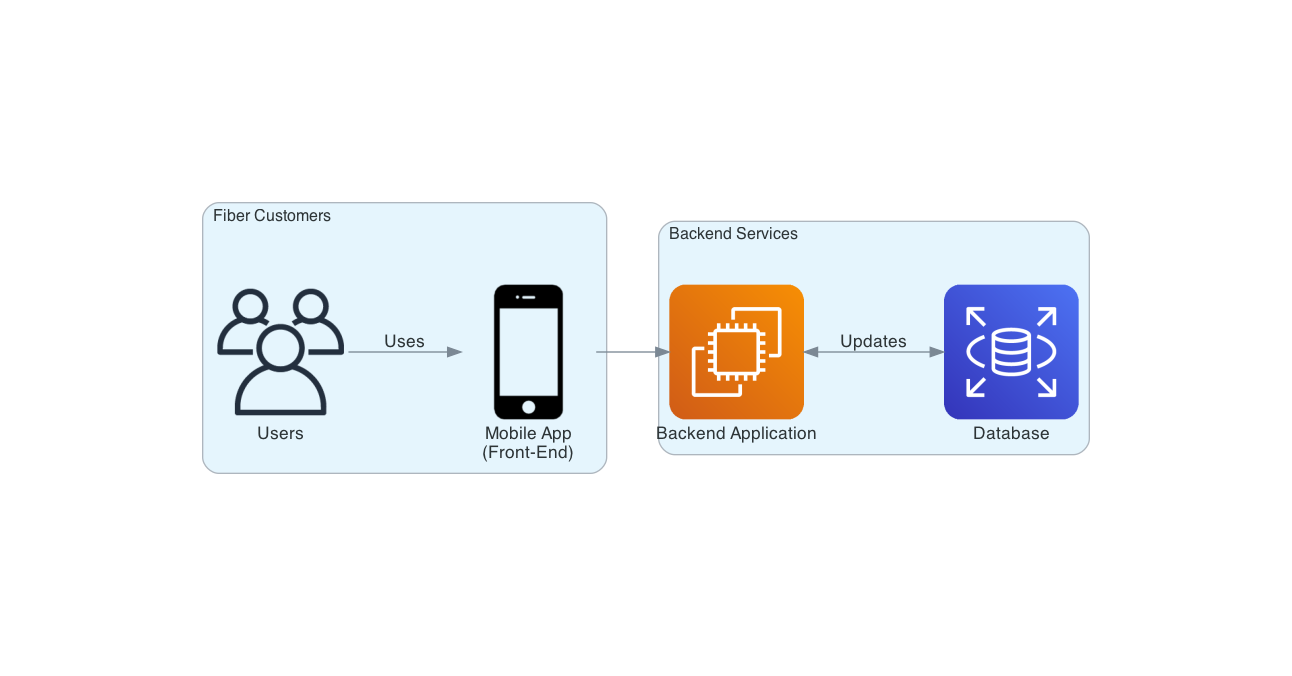
Nothing too crazy here. This is something we all may have experienced before in some capacity (professional or otherwise). The best thing about this architecture is that in many cases, it just works! Our customers are happy that the app is bringing them value via the ability to easily manage their account through the app instead of having to call in and speak with a representative. Additionally, our business is happy that our customer base is growing as a result of our easy-to-use application, giving us an edge on the competition. Thus, we're all on cloud 9. Overall a great success. But what happens next after success?
Where there is success, there is growth! Just because something is successful doesn't mean it's finished. Software is rarely considered finished.
Consider the following, with the success of our application, our business now sees an opportunity to introduce another actor into the space (another revenue stream). This time, instead of only serving fiber customers, we will now introduce fiber installers to our workflow. Our fiber installers have their own front-end application (a tablet) that has access to the same tools and services offered to our fiber customers. With the added bonus that fiber installers can provide a discounted rate to our customers when onsite.
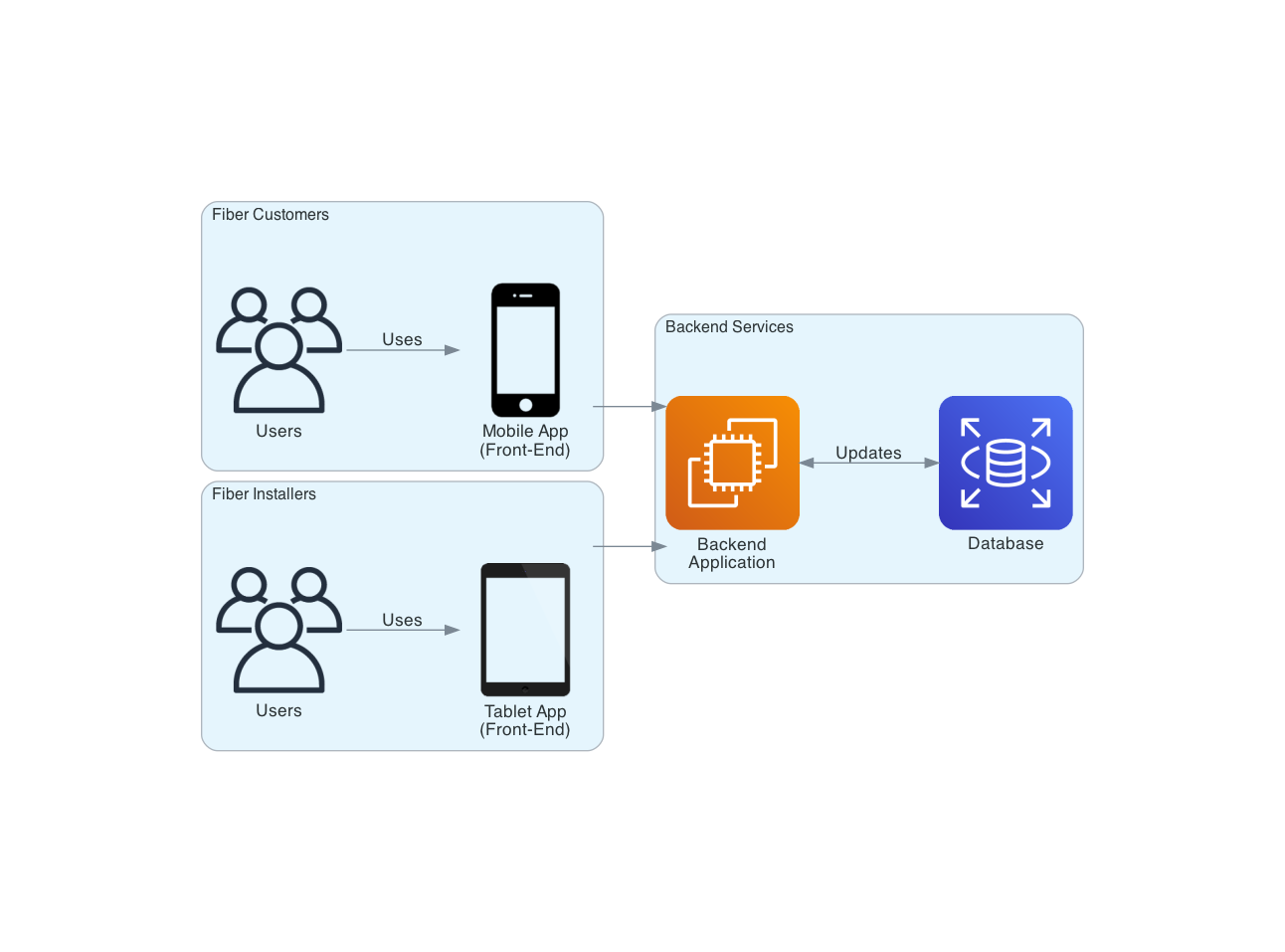
Here's where conflict starts. It may not be so simple to just change the rate for our services depending on the actor. Installers need access to their own billing methods and options. These billing methods should not interfere with those that already exist for fiber customers, or the business could potentially lose a fair chunk of change by charging incorrect amounts to our customers. Suddenly, to make this seemingly simple change requires an expensive and time-consuming regression test!
The result? Changes are slower, more expensive, and become progressively more taxing on our common infrastructure. However, we do have a solution!
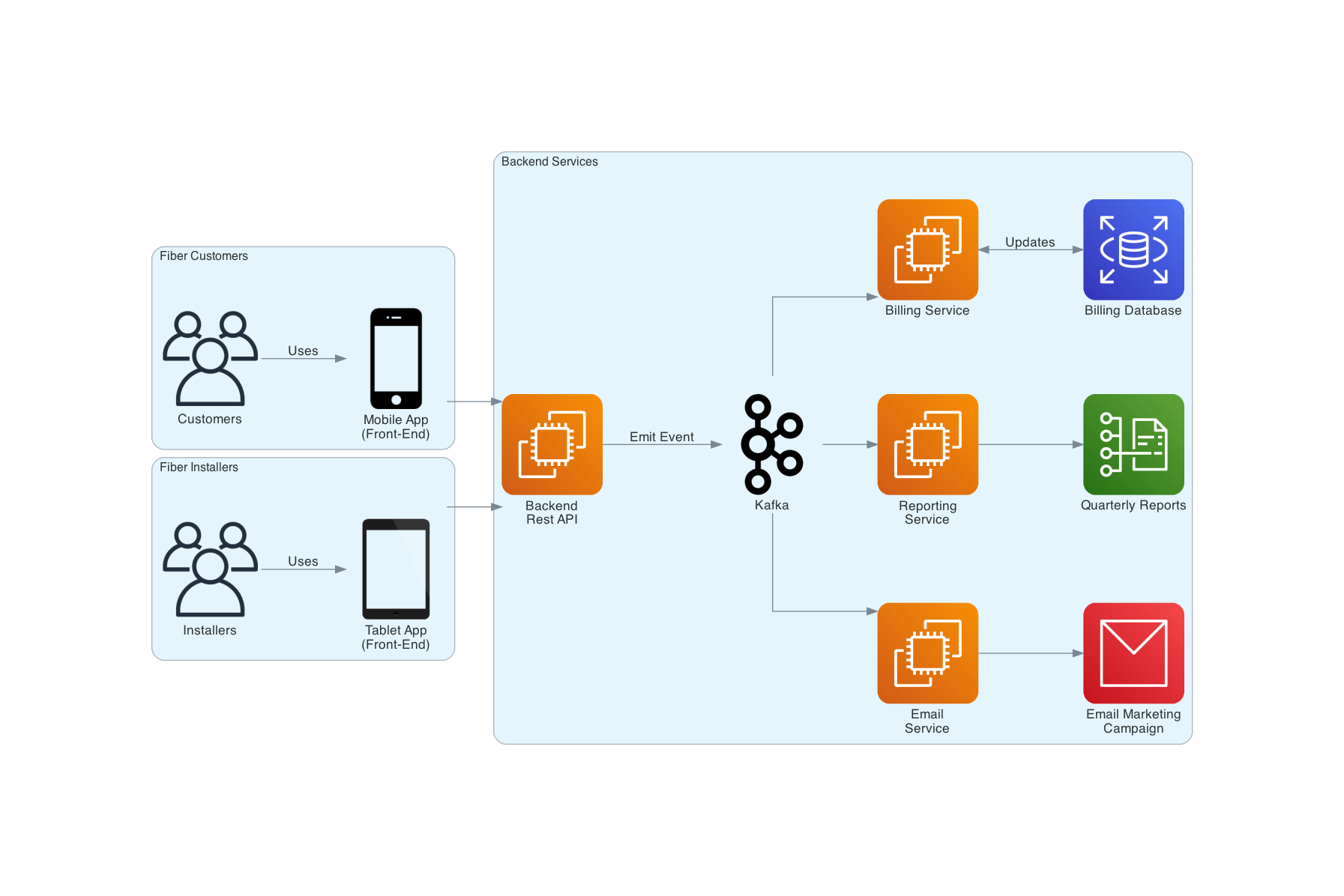
In comes our event-broker (Kafka). For those unfamiliar, Kafka is a distributed event streaming platform, meaning that it's an expert at distributing messages from system to system in near real-time. With Kafka, we introduce an event-driven backbone for service-based architecture. This backbone is the piece that finally allows us to decouple our actors from each other by promoting the production, detection, consumption of, and reaction to events ( Event-Driven Architecture ). We do so by first modifying our original application architecture. The backend REST API that our actors used to communicate with no longer handles the complex business logic and operations it did in the past. Instead, that service will now emit events onto our backbone. These events provide a bunch of information, such as what action was performed and by whom. Multiple services can choose to listen to specific Events emitted onto Kafka, and those services can choose to perform actions on those events. By changing our architecture from a request-reply model to an event-driven model, our actors are now fully decoupled from one another.
For example, we now have the capability of separating our billing service for customers and installers. The billing service for customers will ignore any events that come from installers and vice versa. No regression tests are necessary as these services are no longer tightly coupled, and better yet, you open your architecture to extensibility. Adding a new feature becomes a mere extension of the infrastructure we have in place. Want a separate email marketing campaign service targeting customers when they browse a new fiber plan? Go right ahead and add a listener to Kafka.
In short, it's all about the actors. Actors determine whether you should even consider adopting event-driven architectures. If you have a large (or rapidly growing) number of actors, then the efforts you put into establishing an event-driven backbone for your organization can be planted, and the fruits of your labor will bloom with each actor introduced to your system.
Now the question becomes, how do we build our Event-Driven Systems at scale?
Originally published on Stories from the Herd